
见微“质”著| 体液生物标志物研究一站式解决方案
阅读:2677
时间:2024-06-14
♦产品介绍
体液是临床科研常用的样本类型,以血液、尿液、唾液最为常见。体液中蛋白质种类丰富,各种蛋白的水平能够反映机体的生理状态和病理变化;采集过程微创甚至无创,患者接受度高;并且其研究成果易于临床应用转化。因优势明显,体液样本是做临床科研的绝佳研究材料。
为方便临床医生和医学研究者充分利用体液样本开展科研,本公司全新开发体液生物标志物研究一站式解决方案,协助客户制定系统的临床科研方案,客户根据方案提供体液样本,后续由公司对样本进行蛋白质组学检测和后续分析。此产品不仅包含机器学习建模和疾病生物标志物筛选,用于疾病诊断和预后预测;还包含各类疾病相关数据库挖掘,用于侧面验证生物标志物。该产品提供的高质量组学数据和报告图表,不仅可以用于论文发表,还可以作为基金申请的前期基础。
♦产品优势
1.系统制定临床科研方案:
充分考虑客户需求,根据研究目的和项目特点,协助制定系统的临床研究方案,由资深临床流行病学专家和统计学专家把关,确保研究方案的科学性和可行性!
2.纳米磁珠7倍提升检测深度:
使用自主知识产权纳米磁珠,实现血液样本低丰度蛋白的高效富集,蛋白定量深度提升7倍!
3.全面升级分析内容:
针对体液样本的特点,在市面常规蛋白质组学分析报告的基础上,大量增加分析项目(80+),其中50%为我司特有分析内容,多角度深入解析数据。
4.多个公共数据库挖掘:
除常规GO、KEGG、DO、STRING、GSEA分析外,拓展7大特色数据库挖掘,适配体液标志物研究,多角度解析疾病机制。
- IMMPORT数据库——进行免疫及细胞因子分析,从免疫炎性方面提供新的疾病解读角度;
* HDPP、TTD、HBFP、DisGeNET、SalivaDB数据库——重点关注体液标志物、药物靶点及疾病相关蛋白;
* HPA数据库——挖掘分泌蛋白组数据,关注蛋白分泌部位。
5.建模方法全面升级:
多种机器学习算法横向比较,综合多个评价参数选择最优模型算法,从上千随机蛋白组合中确定最佳生物标志物组合,用于建立最优模型,为疾病的诊断和精准治疗提供重要依据。
♦报告结果示例
(1) 人群临床特征和蛋白定量信息总览
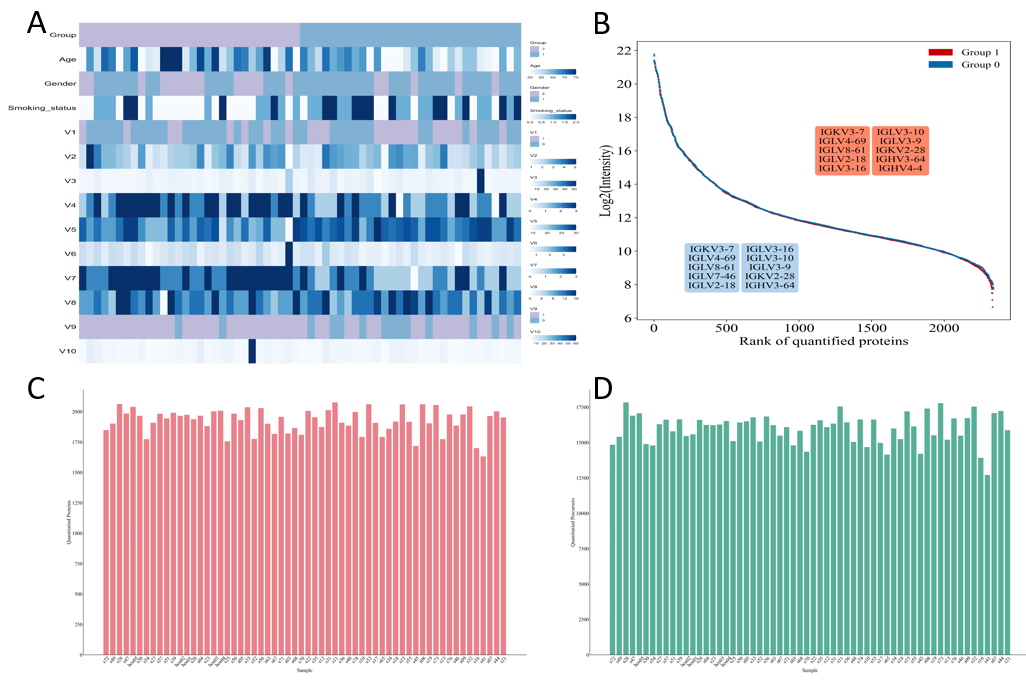
通过定量热图可视化临床变量(图A);蛋白动态范围分布图分别标注每组中含量排名前十的蛋白基因名称(图B);直方图展示各样本蛋白质组定量数据情况(图C、D)。
本结果可用于展示项目样本的临床信息及项目检测到的所有样本中蛋白质组数据定量的总体情况。
(2) 差异蛋白分析
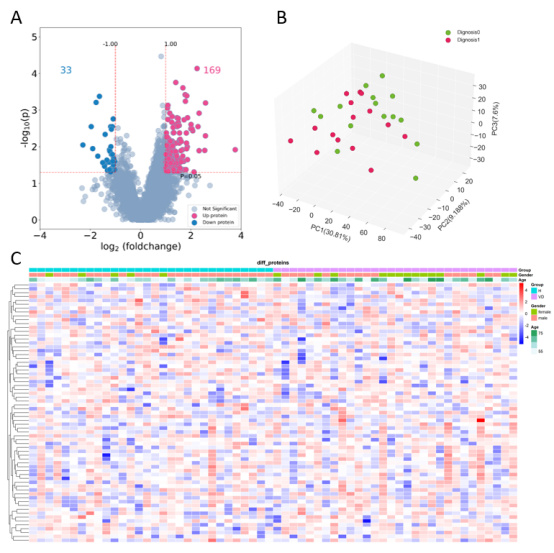
根据蛋白的组间差异倍数和P值筛选差异蛋白,并通过火山图(图A)、主成分分析图(图B)以及聚类热图(图C),综合展示差异蛋白的表达情况及样本之间的差异情况。
本结果用于展示组间差异蛋白的分析结果,通常选择两组间差异倍数和P值排名都靠前的蛋白,作为后续验证和功能探索的候选蛋白。
(3) 疾病关联蛋白筛选
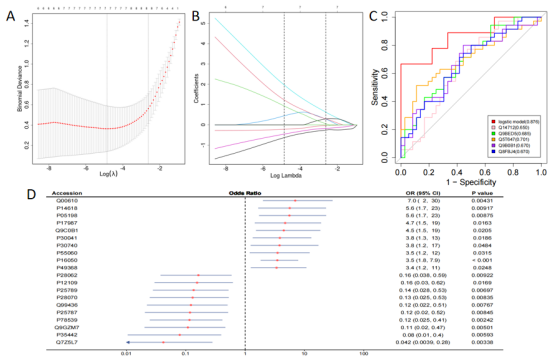
利用Lasso回归进一步筛选差异蛋白(图A、B);ROC曲线和单因素Logistic回归森林图展示单个蛋白与疾病之间的关联(图C、D)。
本结果用于展示经Lasso回归筛选的差异蛋白,以及蛋白对疾病的区分能力及与疾病的相关性。
(4) 最佳建模算法选择
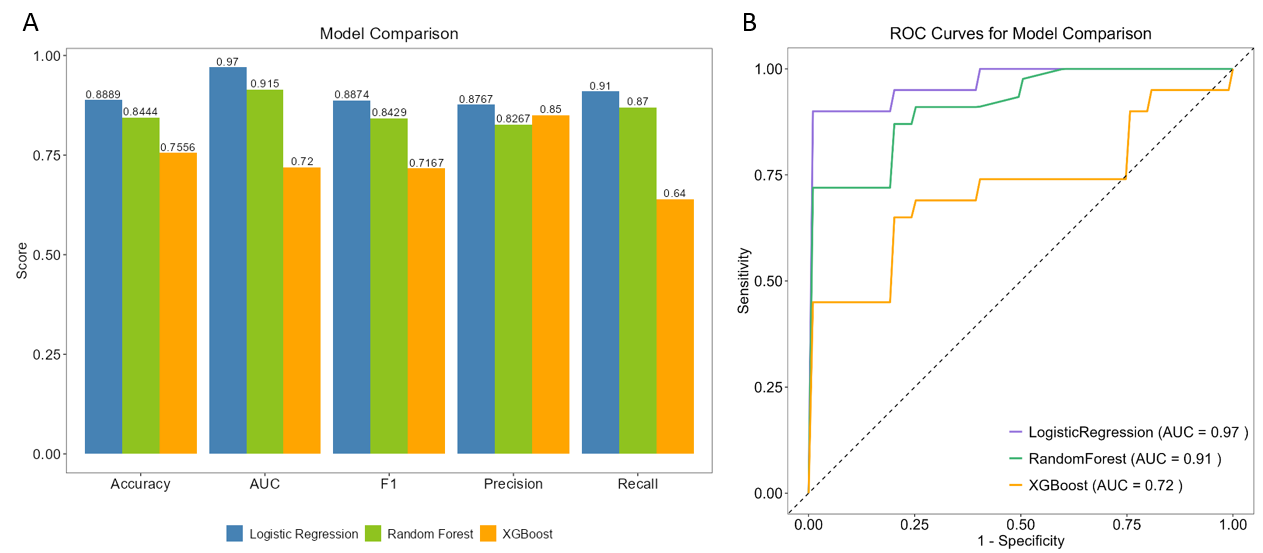
基于lasso回归筛选的候选标志物,使用Logistic回归、随机森林和XGBoost多种算法建模,并通过柱状图比较各模型的准确度(Accuracy)、召回率(Recall)、精确率(Precision)、F1值(F1 Score)和曲线下面积(AUC)(图A),用折线图展示多种算法的AUC值(图B),选择AUC值最大者作为最佳算法。
本结果展示不同机器学习建模算法的比较结果,筛选出最佳算法用于下一步最佳标志物组合的筛选。
(5) 模型构建及评价
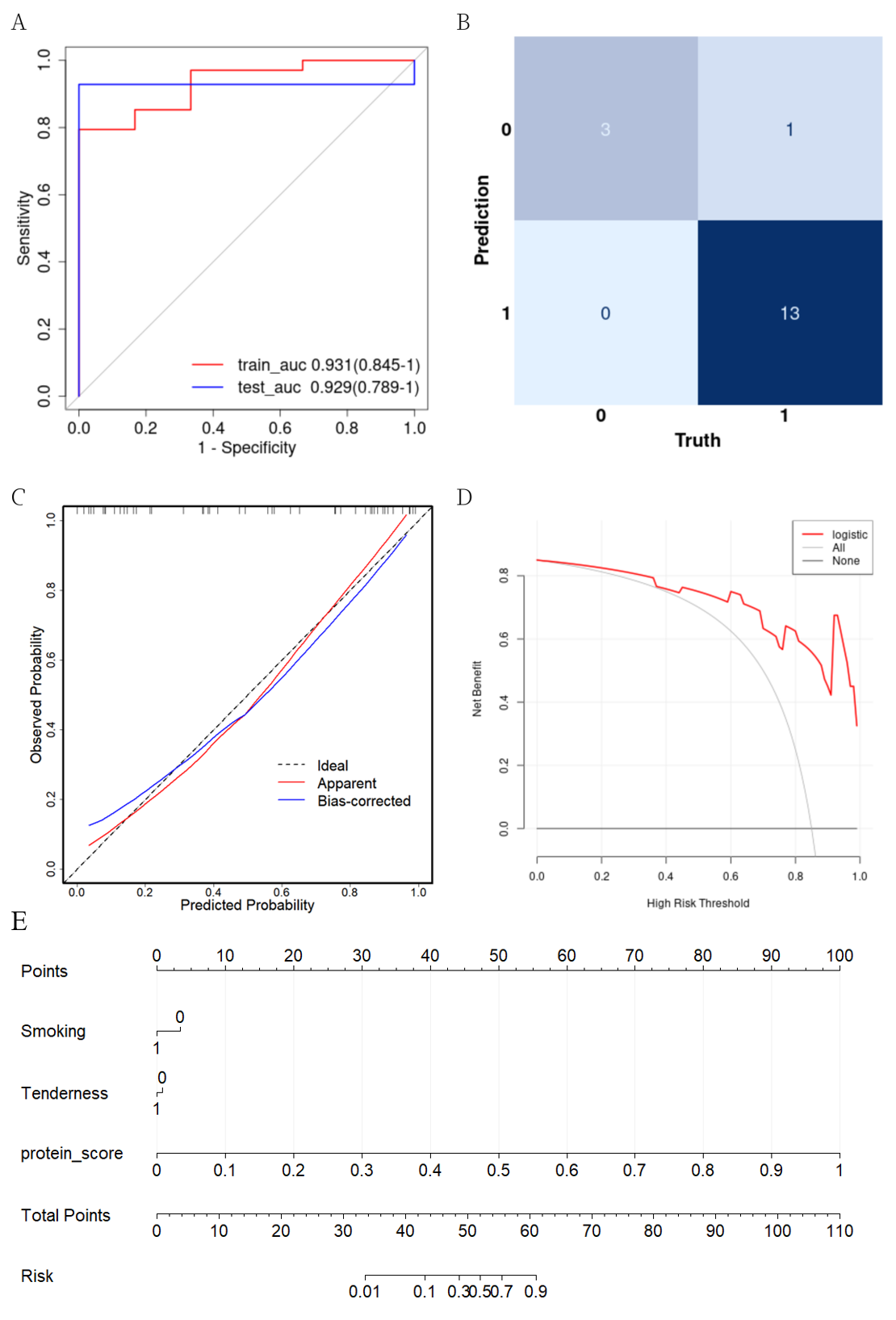
将Lasso回归筛选出的候选蛋白在一定规则下随机组合,基于最佳模型算法从几千种组合中筛选出最佳组合,构建临床模型(图E),并从区分度(图A、B)、校准度(图C)以及临床效应(图D)三个方面对模型进行评价。
本结果展示构建最优临床模型的过程及模型评价的结果,此模型后续可用于对所研究疾病的诊断或预后预测,也是后续研究中需要在新的独立队列中验证的模型。
(6) 注释富集分析
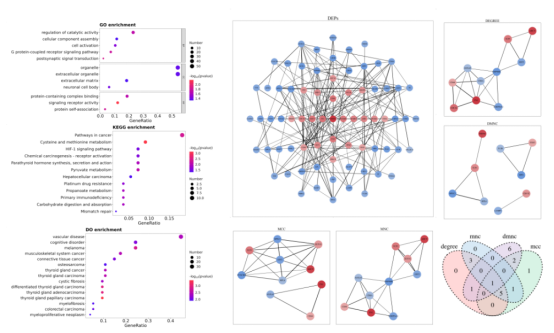
基于GO、KEGG、DO数据库,从多个层次对差异蛋白进行注释和富集分析,气泡图展示差异蛋白富集的功能条目以及信号通路信息(左图);PPI互作网络图(右图)展示差异蛋白之间已知或可能存在的相互作用关系,并使用Cytoscape中的4种算法,从不同角度为客户提供核心蛋白挑选建议。
本结果用于展示差异蛋白所属的功能条目、信号通路及相互作用关系,从分子机制角度解析组学数据。后续可挑选排名靠前的功能条目和互作网络中的核心蛋白,开展进一步研究验证。
(7) GSEA分析
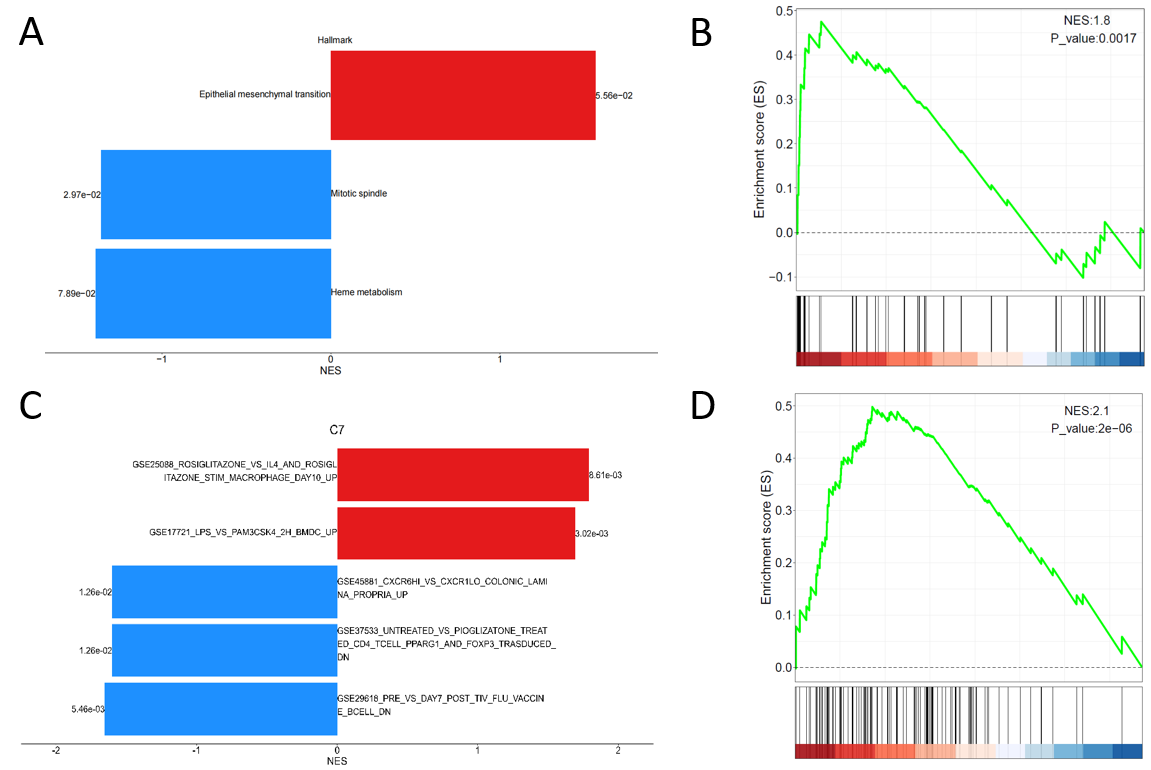
基于Hallmark基因集、C7免疫基因集和蛋白质组定量数据进行GSEA分析,展示富集到的组间上下调的所有基因集条目(图A、C),以及富集程度最高通路条目的GSEA富集结果(图B、D)。GSEA分析更关注通路中蛋白的整体变化趋势,是对传统富集分析的重要补充。
本结果展示蛋白质组学数据GSEA分析的结果,提示组间有重要变化的功能条目和信号通路的整体上下调情况,后续可选择评分靠前且P值较小的通路开展进一步研究。
(8) 多个疾病相关数据挖掘
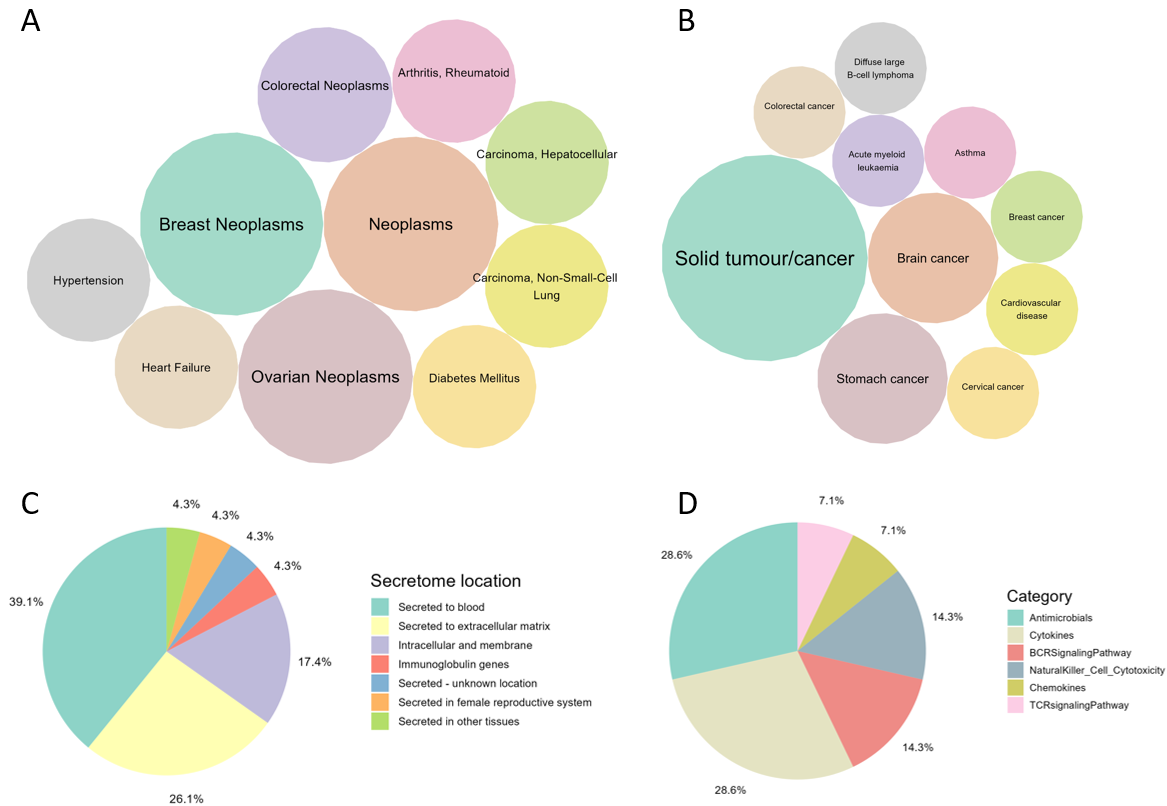
在Human Disease Plasma Protein(HDPP,图A)、Therapeutic Target Database(TTD,图B)、Human Protein Atlas(HPA,图C)、The Immunology Database and Analysis Portal(IMMPORT,图D)、Disease Gene Network(DisGeNET)、Human Body Fluid Protein(HBFP)、SalivaDB多种疾病相关数据库中挖掘差异蛋白信息,展示差异蛋白主要关联的疾病、分泌蛋白的分泌的部位、细胞因子种类、药物靶点等信息。(此处仅展示部分数据挖掘结果)
本结果展示多种疾病相关数据库挖掘的结果,提供丰富的疾病相关信息,是组学数据的有力补充,为生物标志物与疾病的关联提供间接验证,也为后续选择蛋白进行深入研究提供参考。
♦产品服务
此次推出的体液生物标志物研究一站式解决方案包含血液、尿液、唾液三大子产品,每种产品依据不同样本类型而选择对应的样本处理方法及适配数据库。需注意的是,建模分析和分子分型分析在样本量过低时临床意义较小,需达到样本例数要求才能提供,具体分析项目见下方表格:
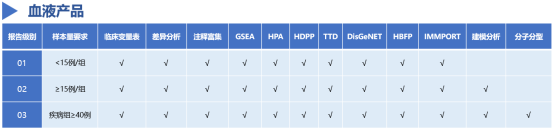
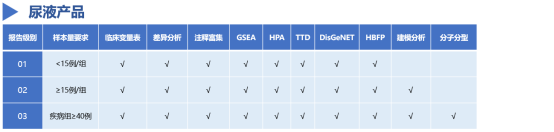
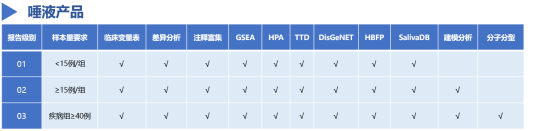
*注释富集包含GO、KEGG、DO以及蛋白互作分析

















